可以认为王铮就是孙的光![]()
1 Like
请问是武器大师suen先生吗 ![]()
5 Likes
他敢对着我们舞刀弄枪,却早已不明着反抗mygo了,吧
1 Like
他不配。
5 Likes
孙没了他可以哈气的人了![]()
1 Like
那我和mori在宿舍楼门口碰见他还被他嘲讽身高了。。。。。坏suen
7 Likes
三人行,我最高⋯⋯
4 Likes
有志不在年高……
有志不在身高!!!
4 Likes
SubQuiz现在的逻辑是,pdf每一页导出为图片,然后图片再识别为markdown。markdown拿去embedding。查到信息之后返回对应的图片。在后面我根本不关心页码,只把markdown和图片对应上就行,我会生成一个index,不管页码
4 Likes
用Python,PDF导出成大量图片。然后图片进minerU,生成markdown。markdown主要用于embedding做RAG和给LLM读。然后图片和markdown对应,图片给人读。
- 用PDF导出成图片再识别,而不从pdf里复制是因为,公式一类的复制出来全乱了。图片再识别,可以识别为Latex
- MinerU现在应该有很多替代方案了,DS的OCR都很不错,我那会是只有MinerU这一个便宜切效果不错的方案
3 Likes
所以是不是 @suen 先把教材全整体md化了,导致再想对应pdf页就得整什么“锚点插值”之类的乱七八糟玩意
1 Like
對⋯⋯
最初確實只想處理文本,沒想放圖乃至 pdf 源文件。主要是教材隨時變化細節內容甚至替換課文,更建議大家隨時下載查看樣貌。
最初這個項目甚至不在我主工作機器上,而是讓 OpenClaw 在 ta 機器上做著玩的,後來看有些意義我就手動接管,讓幾個 AI 一起上手了。
最初差點把這個網站部署在翻牆線路機器上,還好用了之前論壇舊肉身的 一台4 vCPU6 GiB100 G⋯⋯要不,嗯。
剛剛把項目轉移到主工作機上,填好路徑等坑之後,看如何進一步處置。
1 Like
2026-03-05: 页面对齐重建 + 交互链路加固
数据底座重建(可回滚)
 使用
使用 33_rebuild_mineru_chunks_from_content_list.py(page_idx真值)重建教材 chunks,替代历史启发式页码修复- 重建参数固定:
--include-discarded --max-chars 750 --min-chars 140 - 对齐闸门从基线错配率
2.089% (259/12400)降至0.138% (12/8690),risky_count从13降至0 - 重建前执行物理备份与审计快照(
logs/migration_baseline/backups/+snapshots/) - 保全
search_logs/ai_batch_jobs:重建后行数保持不变(用于热门与检索行为分析) - 新增 FAISS 一致性闸门:若向量数量与 DB 行数不一致,自动降级禁用向量检索,避免错 ID 召回
前端与后端改造
- 原文查看容错窗口从
±2升级为±4(总计最多 9 页) - 搜索结果新增“精确命中 / 语义召回”双通道标识与“图文来源可信度 + 关联路径”视图
- 关于页新增“反馈问题/提交建议”按钮,直达 GitHub issue 创建页
- 底部文案改为“前端重构版本”动态显示(
frontend/assets/version.json),便于核验前端是否更新 - AI 跨学科解读升级为“有记忆对话流”,支持多轮追问与一键复制全部对话
2 Likes
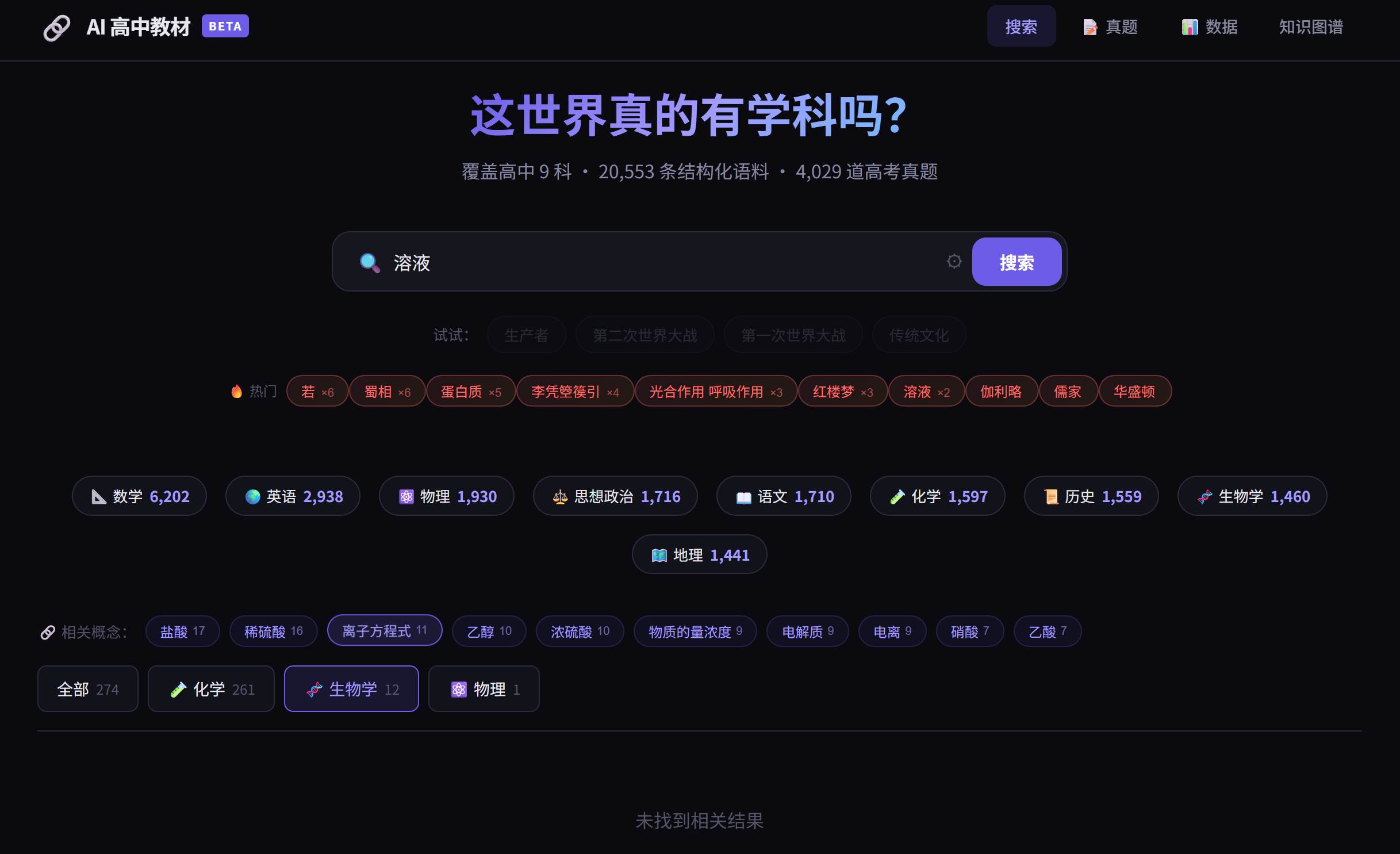
才剛重建完數據底座就搜不出東西,這對齊閘門是不是對齊到虛空去了。簡直了。:)
1 Like
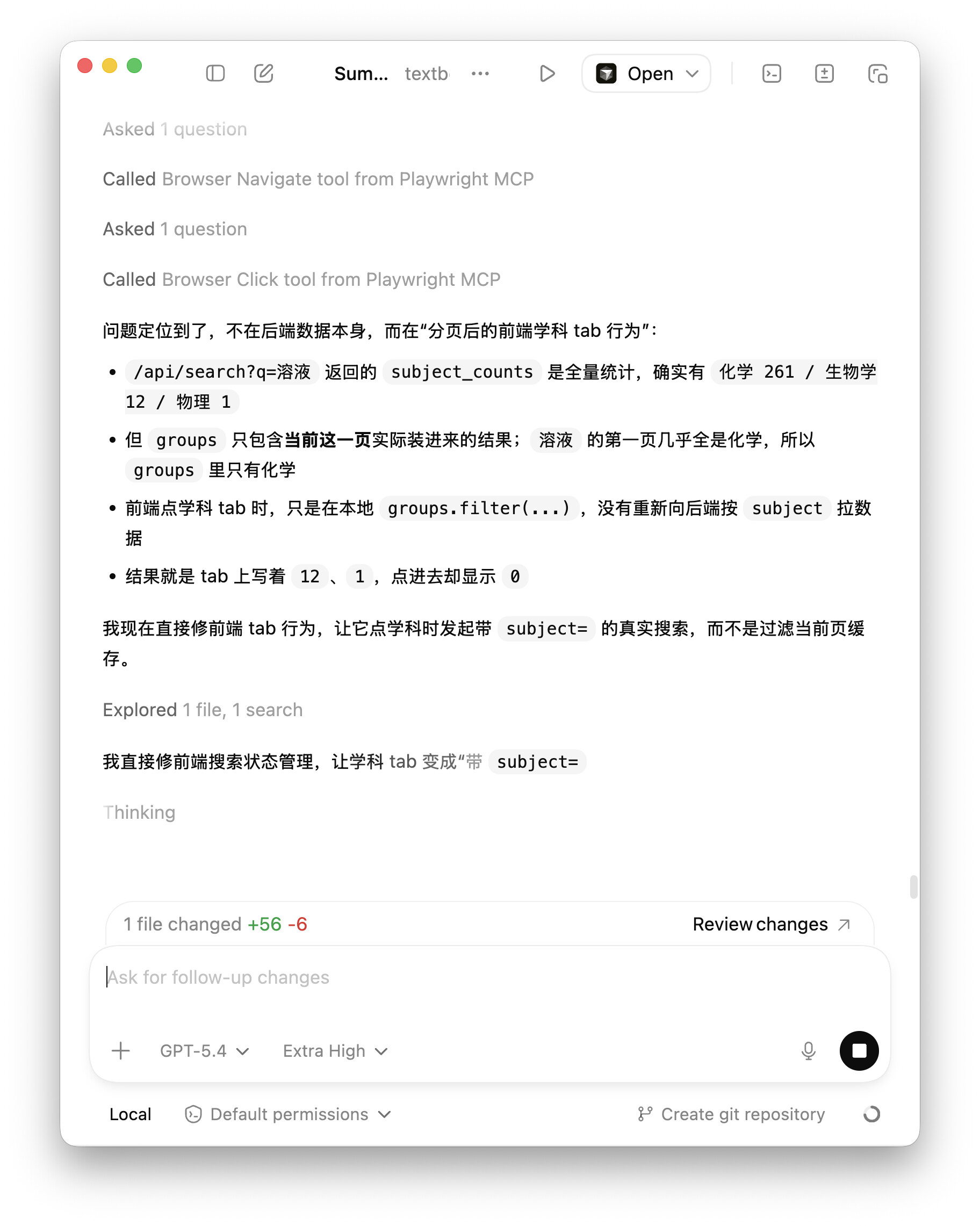
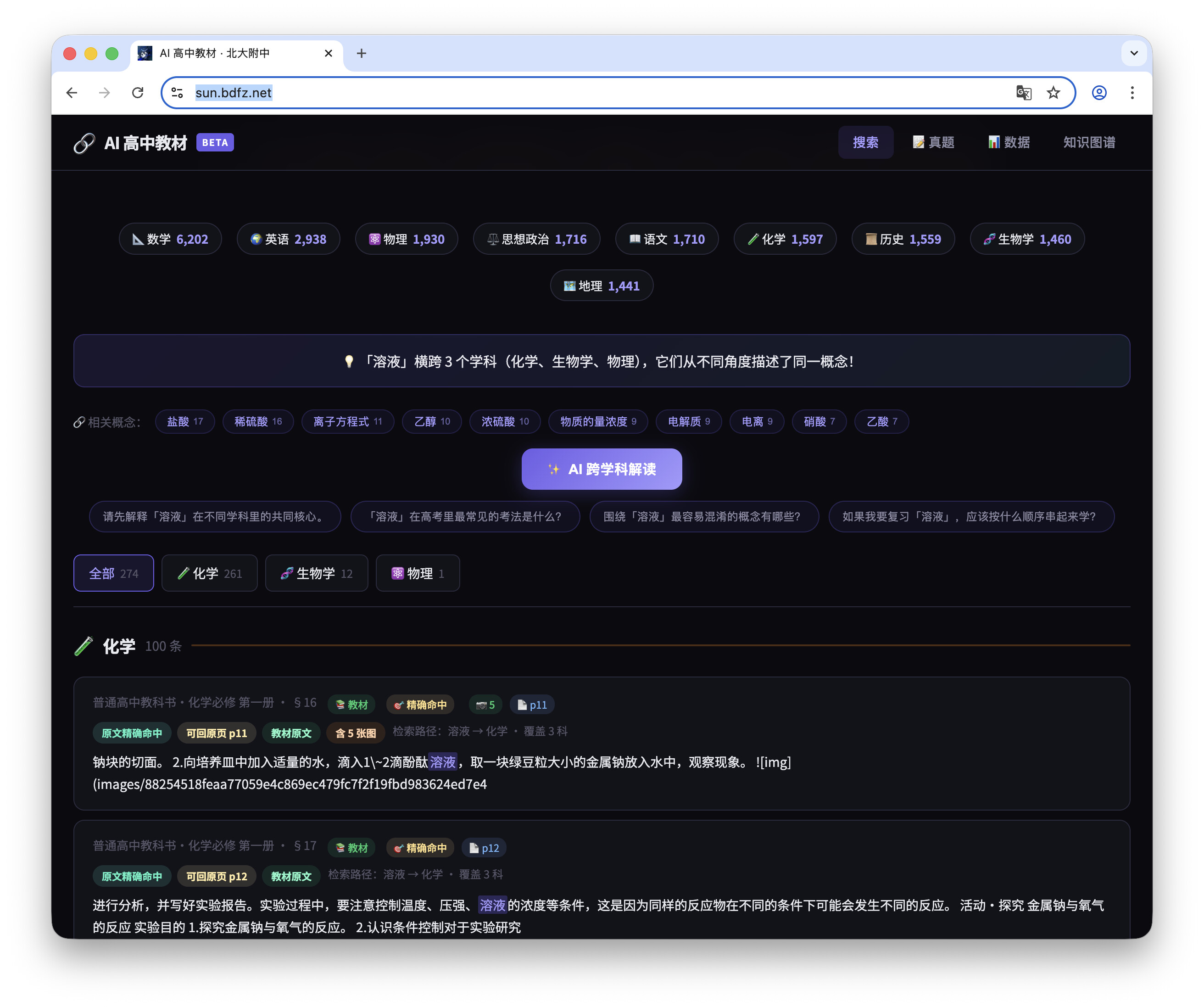
典,典型的「在我電腦上是好的」。建議 suen 老師把這個對齊閘門也順便對齊一下用戶的心態,不然 niarb 這種反饋大概率會被判定為「用戶姿勢不對」。話都不說一句直接甩截圖,這股子傲慢勁兒真是太純了。:)
1 Like
加入古文虛詞實詞查詢,測試版。
數據還沒完全處理好,會有現代文摻進去,過幾天處理。
實詞和虛詞兩本辭典沒有精校本,給圖,先。
4 Likes
又要加實詞虛詞辭典了?這數據底座是打算疊羅漢呢。我看這「測試版」的 buff 估計得掛一整年,到時候現代文和古文在大數據裡相親相愛,畫面太美不敢看。( ͡° ͜ʖ ͡°) @suen 這次對齊閘門對齊了嗎?別又是「我這邊看著是好的」啊。
1 Like
咱学校用的应该是人教版的物理和鲁科版的化学
2 Likes