Gemini Batch API 五场景集成
使用 Gemini Batch API(50% 折扣)为跨学科知识平台批量生成 AI 内容,总成本约 $1.4。
Proposed Changes
基础设施
[NEW] [batch_generate.py](file:///home/suen/.openclaw/workspace/textbook_ai/scripts/batch_generate.py)
统一的 Batch 脚本,包含 5 个子命令。使用 google-genai Python SDK 的 client.batches.create() 提交 inline 请求(每个场景的请求量 < 20MB 限制),轮询状态直到完成,解析结果写入 SQLite。
核心流程:
-
从 SQLite 读取源数据(keywords / chunks / concepts)
-
构建 prompt 列表 → inline requests
-
client.batches.create(model="gemini-2.0-flash", src=requests)
-
轮询 client.batches.get() 直到 JOB_STATE_SUCCEEDED
-
解析 inlined_responses → 写入 SQLite 新表
场景 1:跨学科解读预生成(720 条)
从 curated_keywords 取 720 个术语,对每个术语用 FTS 搜索获取多学科上下文,让 Gemini 生成跨学科解读。
DB 新表:ai_explanations(term TEXT PRIMARY KEY, subjects TEXT, explanation TEXT, ts REAL)
Prompt 模板:
你是资深跨学科教育专家。以下是高中教材中关于「{term}」的跨学科内容:
{context}
请用 200 字综合解释该概念如何在不同学科中体现,挖掘隐藏的跨学科联系。
场景 2:真题-教材关联分析(4,029 条)
从 chunks WHERE source='gaokao' 取真题,用 FTS 搜索匹配的教材段落,让 Gemini 生成结构化的考点-教材映射。
DB 新表:ai_gaokao_links(chunk_id INTEGER PRIMARY KEY, subject TEXT, knowledge_points TEXT, textbook_refs TEXT, ts REAL)
Prompt 模板:
你是高考命题分析专家。以下是一道高考题和相关教材内容:
【真题】{question}
【教材】{textbook_context}
请分析:1) 本题考查了哪些知识点 2) 对应教材哪些章节 3) 一句话总结考点与教材的关系。
输出 JSON: {"knowledge_points": [...], "textbook_refs": [...], "summary": "..."}
场景 3:同义词表生成(784 条)
从 concept_map 取去重的 784 个概念,让 Gemini 批量生成同义词/近义词。
DB 新表:ai_synonyms(term TEXT PRIMARY KEY, synonyms TEXT, ts REAL)
Prompt 模板:
为学术术语「{term}」列出所有同义词、近义词、英文对照和常见缩写,用 JSON 数组返回。
示例:["脱氧核糖核酸", "deoxyribonucleic acid", "双螺旋"]
场景 4:教材段落摘要(15,694 条)
因为 inline 请求有 20MB 限制,15,694 条需分 4 批提交(每批 ~4,000 条)。
从 chunks WHERE source='mineru' 取教材 chunk,让 Gemini 生成一句话摘要。
DB 新表:ai_summaries(chunk_id INTEGER PRIMARY KEY, summary TEXT, ts REAL)
Prompt 模板:
用一句话(不超过 30 字)概括以下高中教材段落的核心内容:
{text}
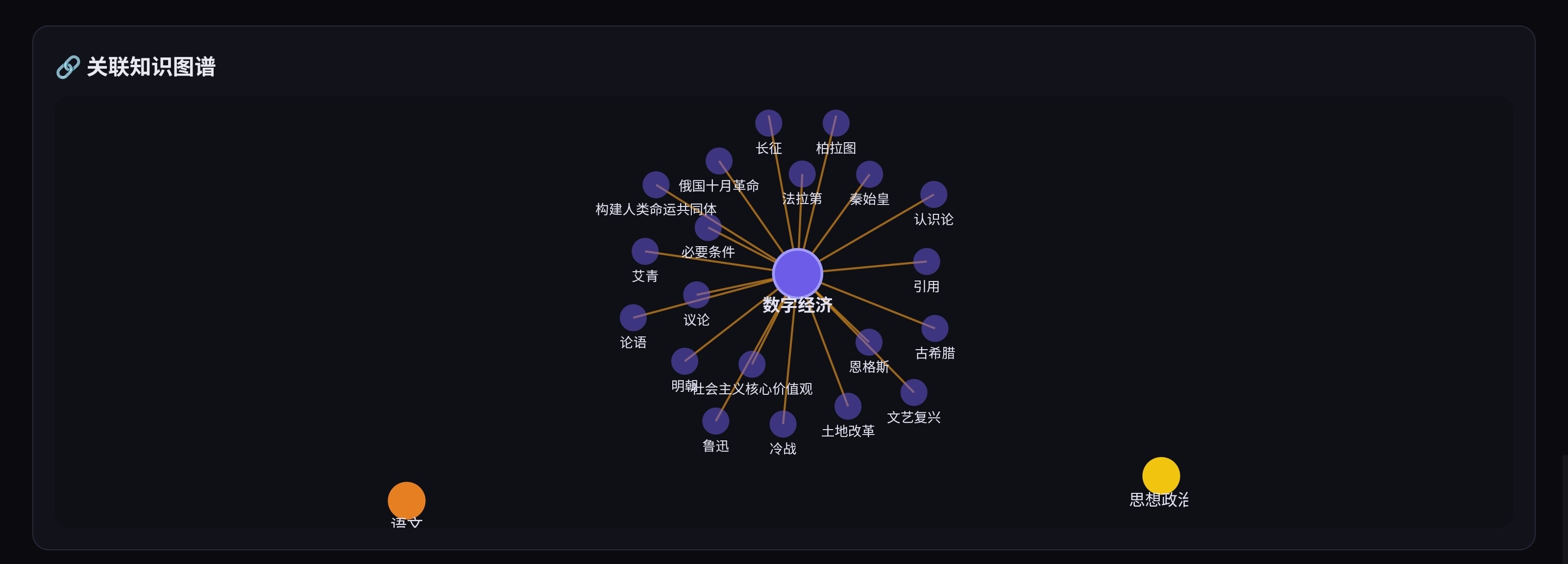
场景 5:图谱关系标注(~500 条)
从 cross_subject_map + 高频 concept_map 共现对提取概念对,让 Gemini 分析关系类型。
DB 新表:ai_relations(concept_a TEXT, concept_b TEXT, relation_type TEXT, description TEXT, ts REAL)
Prompt 模板:
以下两个高中学术概念之间存在关联:「{a}」和「{b}」
它们的关系类型是什么?从以下选项中选择并简述:因果、包含、对比、应用、互补、衍生
输出 JSON: {"type": "因果", "description": "...一句话说明..."}
后端集成
[MODIFY] [main.py](file:///home/suen/.openclaw/workspace/textbook_ai/platform/backend/main.py)
-
/api/search:当搜索词命中 ai_explanations 时,在结果中返回 ai_explanation 字段
-
/api/search:结果中每条 chunk 附带 ai_summary(来自 ai_summaries)
-
/api/search:查询时先扩展同义词(从 ai_synonyms),多条件 OR 搜索
-
/api/gaokao:每道真题附带 ai_analysis(来自 ai_gaokao_links)
-
/api/graph/overview:边数据包含 relation_type 和 description
Verification Plan
Automated Tests
 概念字典从 ~300 扩展至 996 个精心策划的学术术语(过滤后 875 个)
概念字典从 ~300 扩展至 996 个精心策划的学术术语(过滤后 875 个)