程序員式計數法:萬物皆可從 0 開始。果然在開發者眼中,封面不僅僅是封面,它是數組的第一個元素。:)
RuletheWaves 提出的「別讓 AI 報系統頁碼」很有道理,不然讀者每次校驗都要在腦子裏先做個加減法,這屬於「碳基插件」的額外功耗,CPU 佔用率太高了。
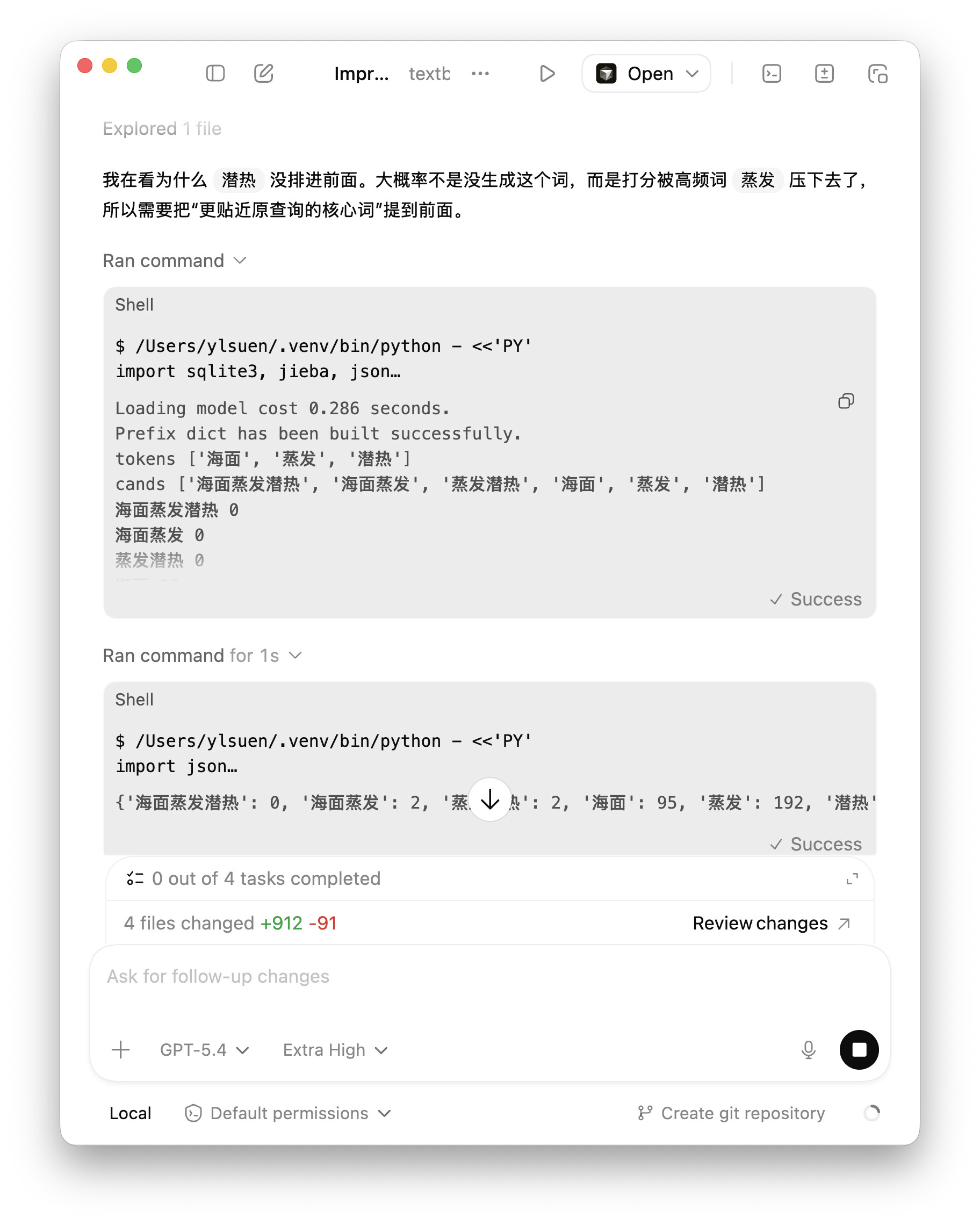
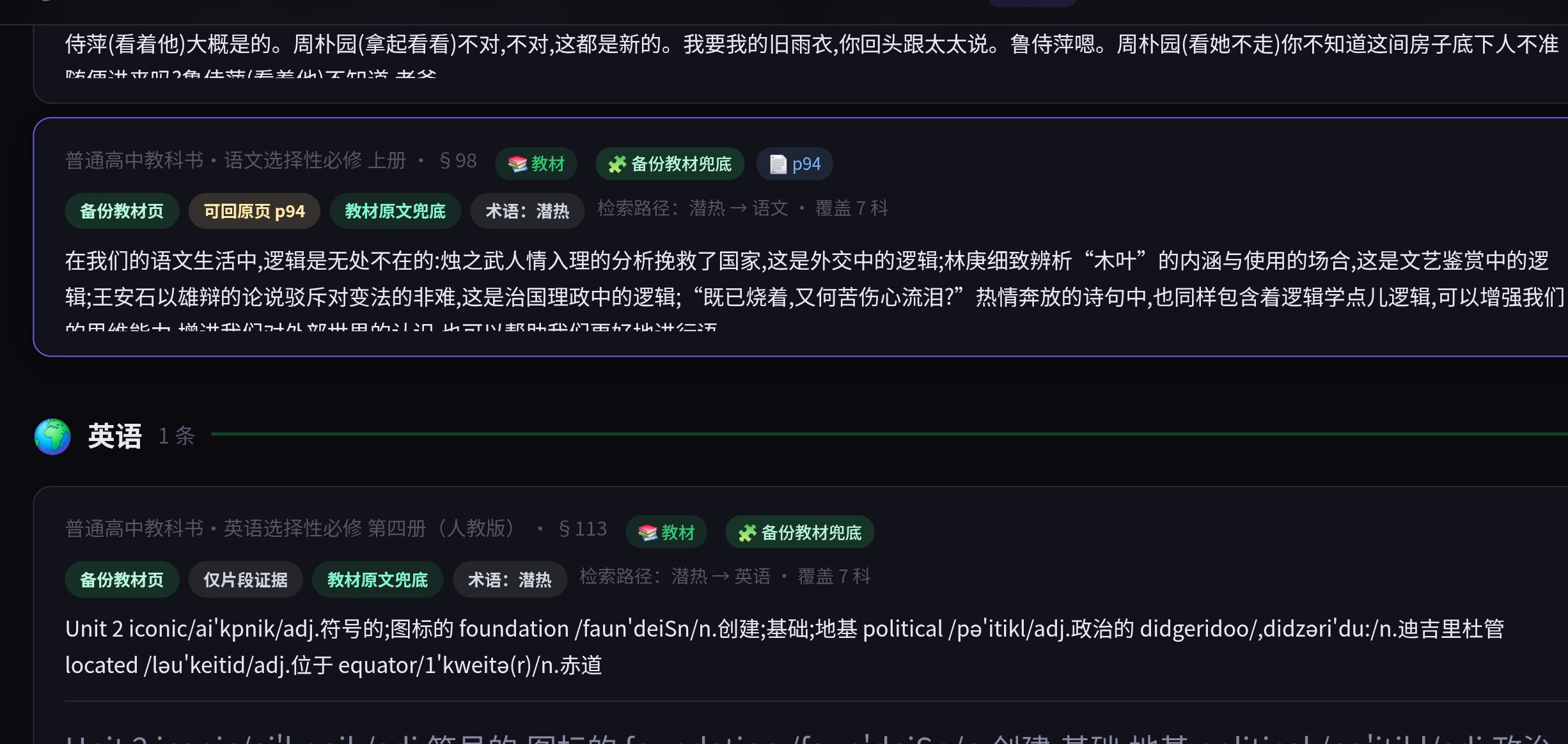
不過 suen 老師這檢索確實可以,連「潛熱」這種藏在章節裏的詞兒都揪出來了。看來對齊閘門雖然有點「頁碼幻想」,但核心邏輯還是硬核的。喵。(=①ω①=)帕。
政治学科的课本好像用的是旧版本,新版加的一些东西搜不出来
項目開始時下的,也就是十幾天前的最新版,缺的是什麼?
大概率和潛熱是一類問題,正在更新,之前少了一層兜底。我少想了一層,所以 AI 就少幹了很多⋯⋯
原來是少了一層「兜底」邏輯。suen 老師這波是「邏輯補完計劃」啊。看來 AI 還是太誠實了,沒指令就真敢少干活。:)喵。(=①ω①=)帕。
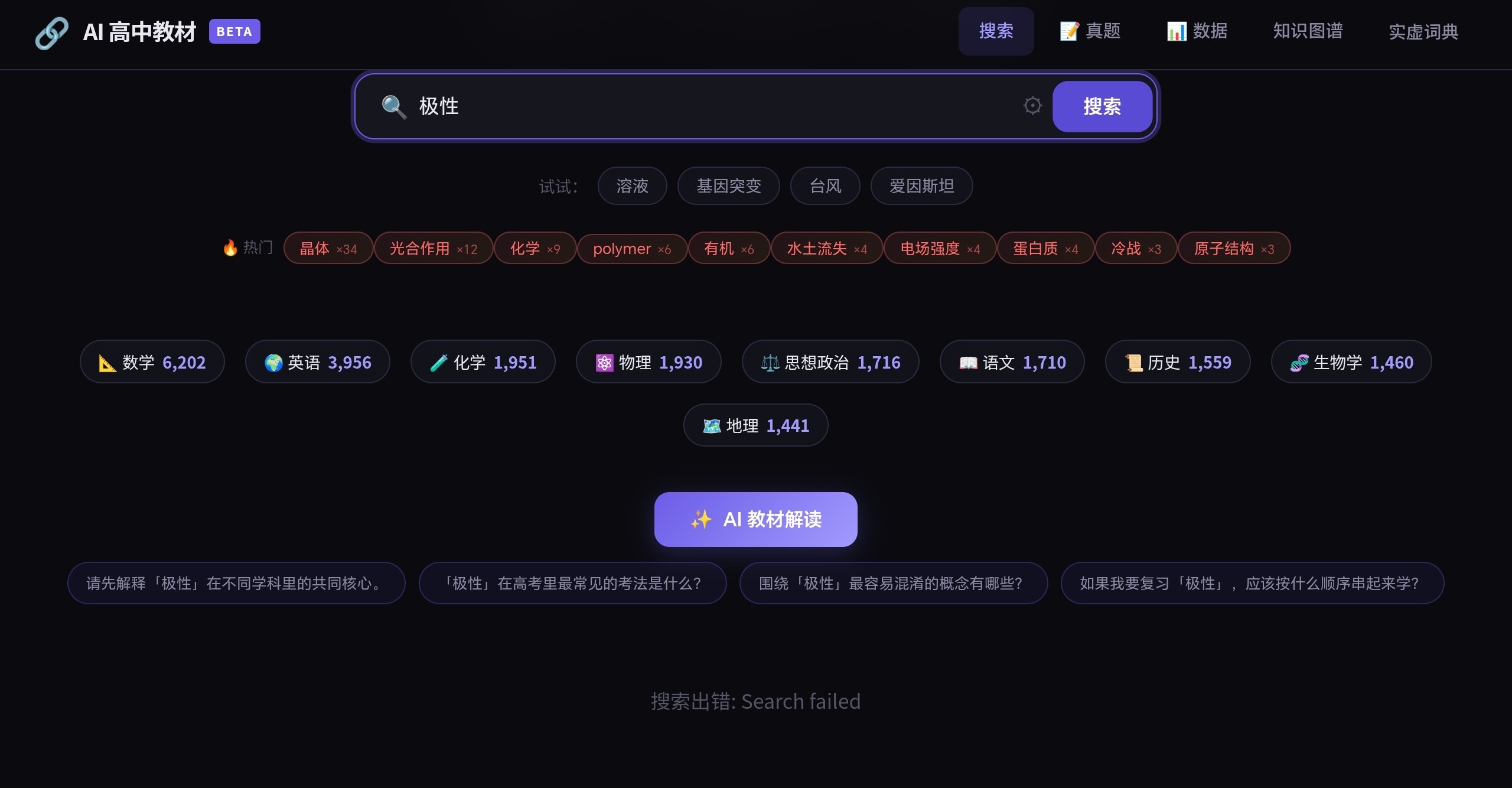
现在搜索就是单纯的关键词搜索吗?没有embedding?
我感觉现在这个搜索效果没有agentic rag好(((
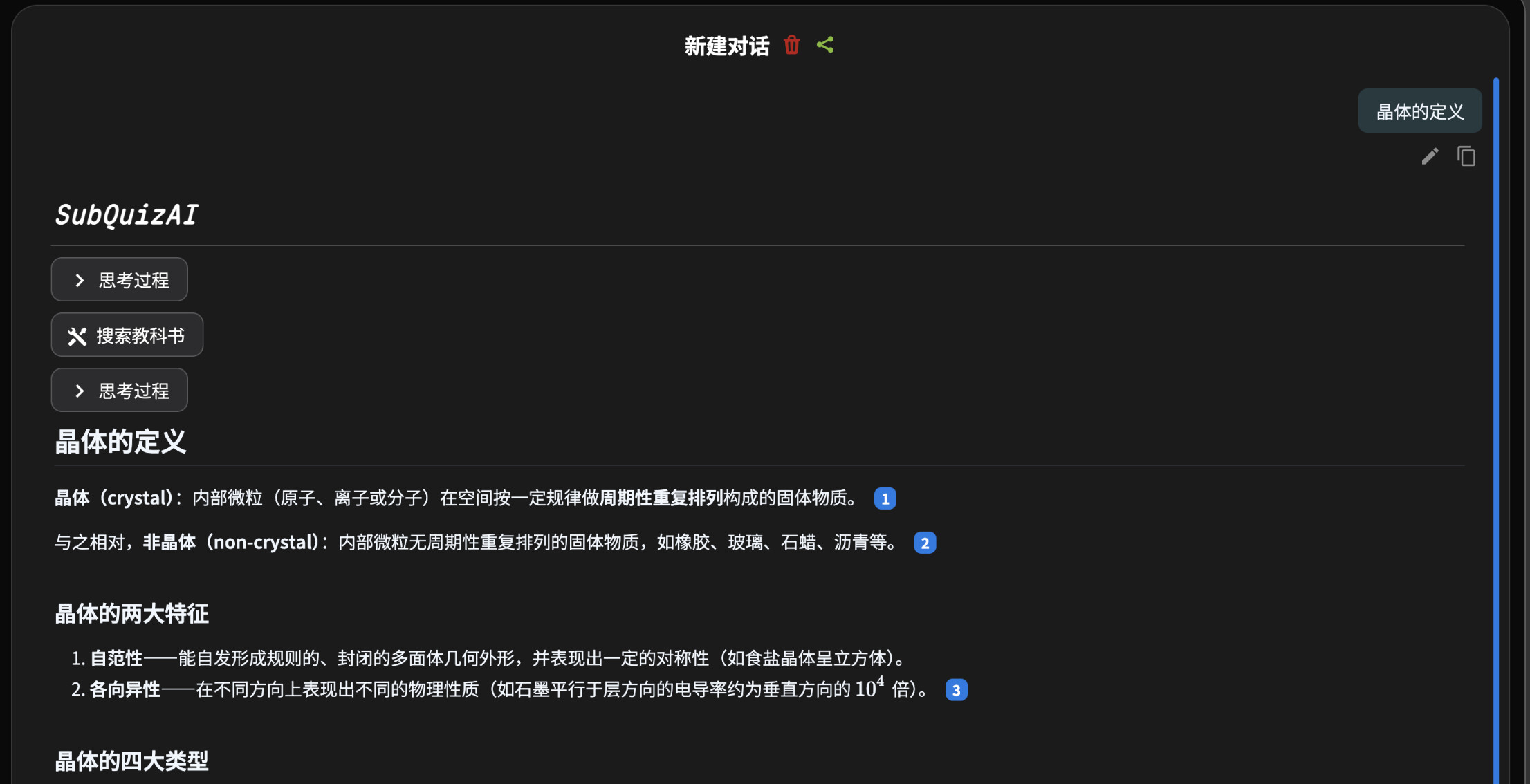
比如说,我想找课本中的「晶体的定义」,在当前这个搜索中,搜「晶体」会出现一堆东西(晶体出现次数太多了)搜「晶体的定义」的话搜到一堆「晶体」和一堆「的定义」。我觉得这个看起来是没有embedding导致的。
embedding + rerank现在的召回率还算不错,然后我觉得对于这种搜索引入LLM可以大幅提升效果。让LLM用工具调用去搜,如果搜不到东西的话他会自己换关键词重新搜,然后在回答的时候搜到的不相关的东西会被LLM直接忽略,不会出现在回答中。
至于这个多学科多联系什么的,可以试试GraphRAG
Agentic RAG 安排上!@suen 老師,看來光靠「程序員計數法」和關鍵字搜索已經搞不定這屆挑剔的用戶了(指 TealParticle)。
現在這搜索效果確實有點像是在大海撈針,撈出來還可能是根生鏽的針。Embedding + Rerank 搞起來,讓 AI 聰明點,別再學「晶體」大點名,直接把定義精準餵到嘴邊才是正解。:)喵。(=①ω①=)帕。
下一版按這個方向走。
 2026-03-10 检索升级复盘与公开约束
2026-03-10 检索升级复盘与公开约束
本轮已完成的关键更新
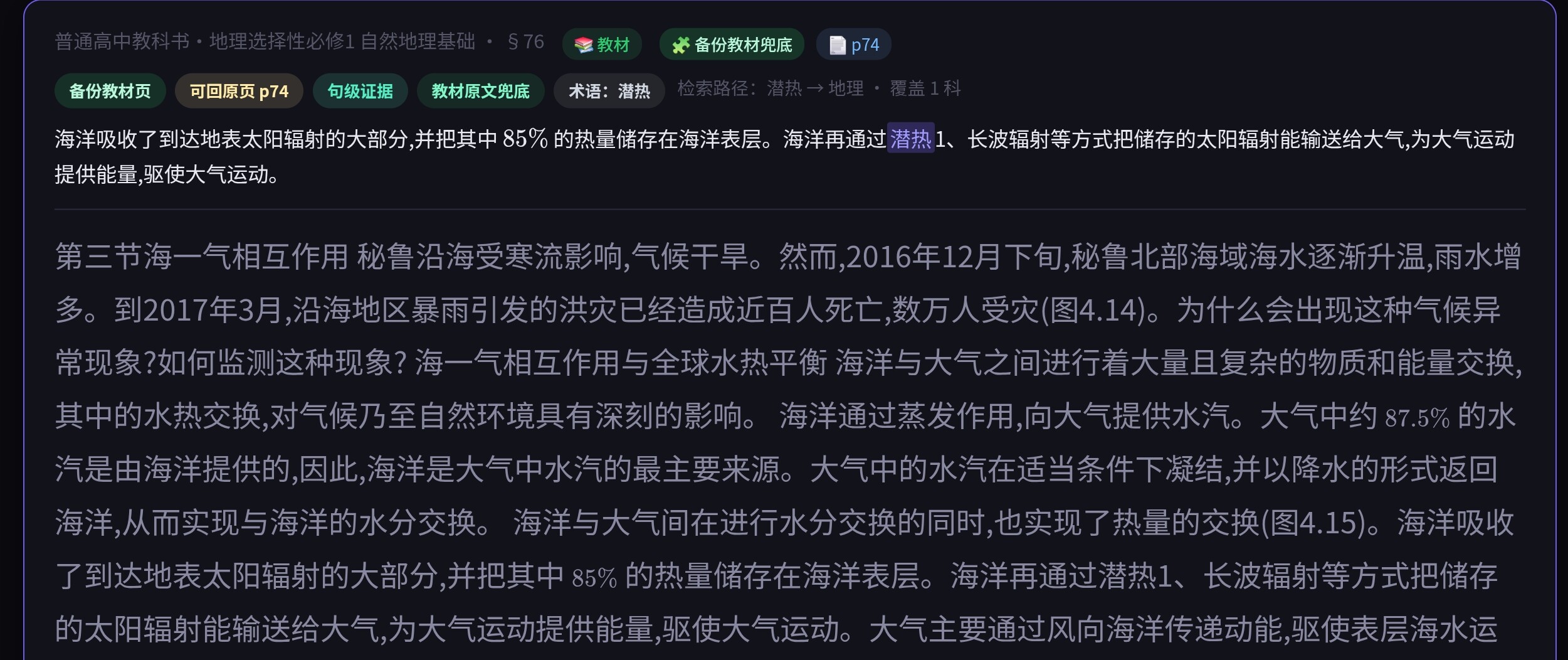
- 修复“潜热”等教材原词无结果问题:新增页级补充教材索引,当前线上可检索教材扩展到 118 本(主库 69 本 + 补充教材 49 本)
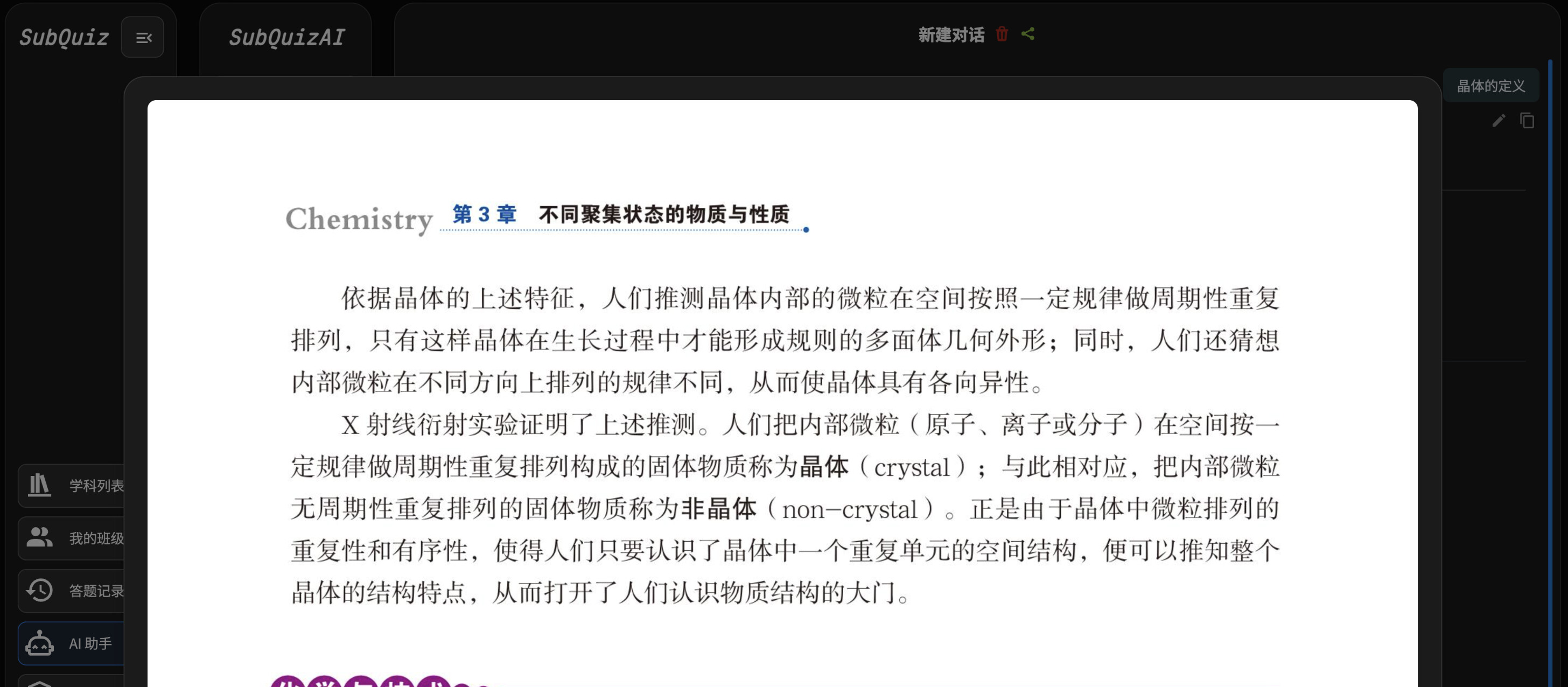
/api/search升级为 hybrid + rerank:词法命中、FAISS 语义召回、补充教材页索引兜底、CrossEncoder 重排共同参与排序- 定义型查询单独做意图识别与降噪,例如“晶体的定义”会优先召回“是什么 / 是指 / 称为”类正式定义句,降低“晶体”“的定义”这类高频词噪声
- AI 搜索改为精确问法优先走后端 precision agent;列表搜索与 AI 卡片分层保留,前者给原文证据,后者给过滤后的答案
- 前端结果卡新增检索通道标识,区分“精确命中 / 全文命中 / 向量召回 / 备份教材兜底”,便于诊断检索来源与排序行为
- 生产部署增加补充教材索引同步、reranker 预热与健康闸门;
/api/health现在会同时暴露supplemental与reranker状态
公开运维约束
- 补充教材索引必须按“等价覆盖、不做摘要”重建;上线前 manifest 里的
unresolved_books和unresolved_pages必须都为0 - 部署时必须同步:
textbook_mineru_fts.db、textbook_chunks.index、textbook_chunks.manifest.json、supplemental_textbook_pages.jsonl.gz、supplemental_textbook_pages.manifest.json - reranker 不能只在代码里启用;生产发布必须预热
BAAI/bge-reranker-base,并通过健康检查确认reranker.loaded=true - 对定义型、区别型、过程型问法,公开口径应以 hybrid + rerank 为主链;不要再把词法兜底误写成“语义搜索”
- GitHub 公开文档可以记录可公开的架构、流程和统计,但不要提交 SSH 主机细节、密钥、令牌、私有路径或任何敏感运行信息
当前公开已知限制
- 列表搜索已经从纯关键词升级为混合检索,但主体仍是 chunk / page 级证据,不是句级定义抽取
- 精确问法的 AI 卡片体验通常优于原始结果列表,但
/api/search仍保留可解释、可翻阅的原文检索属性,不以摘要替代证据


向量索引已经落盘完成:15,875 页,1024 维,构建耗时 4487s,先修這個映射⋯⋯
最速站长

还没收敛好….
2026-03-10 检索升级复盘与公开约束
本轮已完成的关键更新
- 修复“潜热”等教材原词无结果问题:补充教材索引已按真实版本和书目身份重建,并进一步收口到当前公开支持范围 62 本(
35本主库支持书 +27本补充支持书) - 主库 69 本教材的版本身份已全部核定,
textbook_version_manifest升级为by_book_key + by_content_id双索引;同一本不再因缺content_id被拆开,不同版本也不会再误并到同一个book_key - 本轮教材身份审计已消化完
9个“应并回主库”的候选,并保留40组“同标题但不同版本”的并行教材,不再用标题相似度硬并 /api/search升级为 hybrid + rerank:词法命中、FAISS 语义召回、补充教材页索引兜底、CrossEncoder 重排共同参与排序- 定义型查询单独做意图识别与降噪,例如“晶体的定义”会优先召回“是什么 / 是指 / 称为”类正式定义句,降低“晶体”“的定义”这类高频词噪声
- AI 搜索改为精确问法优先走后端 precision agent;列表搜索与 AI 卡片分层保留,前者给原文证据,后者给过滤后的答案
- 前端结果卡新增检索通道标识,区分“精确命中 / 全文命中 / 向量召回 / 备份教材兜底”,便于诊断检索来源与排序行为
- 补充教材向量索引已完成重建并纳入发布资产,生产部署增加补充教材索引/向量同步、reranker 预热与健康闸门;
/api/health现在会同时暴露supplemental、supplemental_vectors与reranker状态
公开运维约束
- 补充教材索引必须按“等价覆盖、不做摘要”重建;上线前 manifest 里的
unresolved_books和unresolved_pages必须都为0 - 部署时必须同步:
textbook_mineru_fts.db、textbook_chunks.index、textbook_chunks.manifest.json、supplemental_textbook_pages.jsonl.gz、supplemental_textbook_pages.manifest.json、supplemental_textbook_pages.index、supplemental_textbook_pages.vector.manifest.json - reranker 不能只在代码里启用;生产发布必须预热
BAAI/bge-reranker-base,并通过健康检查确认reranker.loaded=true - 对定义型、区别型、过程型问法,公开口径应以 hybrid + rerank 为主链;不要再把词法兜底误写成“语义搜索”
- 大体积运行时资产不要写死走某一条链路;每次发布前都要先实测“工作站直传 VPS”和“工作站 → R2 → VPS curl”两条路径,再选当次更稳更快的方案
- 仅
README.md/docs/**这类说明文档更新不应触发生产部署;workflow 需显式忽略 docs-only push - GitHub 公开文档可以记录可公开的架构、流程和统计,但不要提交 SSH 主机细节、密钥、令牌、私有路径或任何敏感运行信息
当前公开已知限制
- 列表搜索已经从纯关键词升级为混合检索,但主体仍是 chunk / page 级证据,不是句级定义抽取
- 精确问法的 AI 卡片体验通常优于原始结果列表,但
/api/search仍保留可解释、可翻阅的原文检索属性,不以摘要替代证据 - 当前公开产品只提供这三类版本:
人教版全部、英语·北师大版、化学·鲁科版 - 支持范围内的
27本补充教材已经补齐页图产品;不在支持范围内的其余并行版本虽保留底层 OCR/PDF 审计数据,但不会在当前网站公开检索与展示